















Share:

.svg)
.svg)

Ever since the start of the year, the top priority for us at APIMatic was to improve the packaging of our products and features. We launched the Developer Experience Portal, added package publishing capabilities to our eco-system, added curl commands to our console, revamped our Developer Portal to optimize loading speeds and so on.
With our new products and offerings, we needed new APIs to allow our users more points of access. This gave us a perfect opportunity to revamp our existing APIs as well, which were developed for internal use only and were never designed to have the perfect structure, naming or performance. However when duty called


we rose up to the occasion and revamped our entire infrastructure to make the perfect little REST APIs.


Goals
Developer Experience is the most important metric to measure the quality of an API. For us at APIMatic it is the rule of law, it’s the word of god, it’s everything. We have always preached the idea of well-designed APIs that are super easy to use and make the life of developers easy. An API is not a random chunk of code, it’s an interface, and like any interface, you need to make sure that the experience you’re providing is as smooth and seamless as possible because that is what developers are looking for.
With developer experience as the goal post, the direction we took for implementing our new APIs was very clear. Let’s briefly look at the fundamental concepts that were under consideration throughout the development cycle:
- Stable and even more importantly Scalable APIs.
- Making our APIs truly RESTFUL by adhering to the constraints of REST as much as possible.
- Ensure backward compatibility for our public APIs.
- Focusing on simplicity, extensibility, reliability, and performance.
- Sticking to popular standards to create uniformity in the code.
- Prioritize naming and making it consistent across the application.
- Improving the readability and structuring of the code to optimize it for incremental upgrades in the future.
- Creating the APIs to be easily testable and then writing Unit Tests for them.
The Richardson Maturity Model
The Richardson Maturity Model is a great way to grade your API according to the constraints of REST. The better your API adheres to these constraints, the higher its score is. The Richardson Maturity Model knows 4 levels (0–3), where level 3 designates a truly RESTful API.
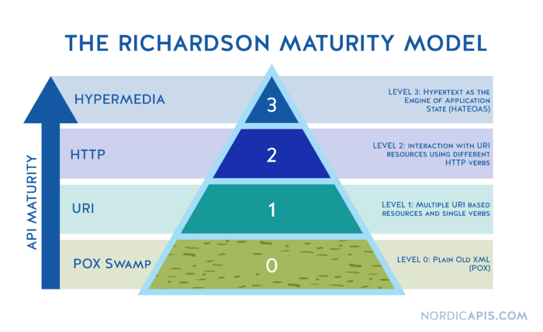
Our previous APIs were Level 0; RESTful only in name as they were only using HTTP to send requests and receive responses without utilizing the full potential of HTTP. The APIs were used only to invoke remote mechanisms based on remote procedure calls. There was some leveling up required, and that’s what we did.
You can read all about the best practices to design your API from scratch here: Best Practices to Increase API Adoption
Resources
A resource is one of the most essential parts of REST. Resource is an object or representation of something, which has some data associated with it and there can be a set of methods to operate on it. According to REST, the URI should only contain resources(nouns) not actions or verbs. The paths should contain the plural form of resources and the HTTP method should define the kind of action to be performed on the resource. We identified our resources to be:
- Transformation: A single resource describing all the relevant information of the Transformation of an API description from one format to another. The transformation is tied to the User.
- API Entity Code Generation: A single resource describing all relevant information of a code generation performed from an API description already stored with us. The API Entity Code Generation is tied to the API Entity for which the SDK is generated.
- User Code Generation: A single resource describing all relevant information of a code generation performed from an API description provided by the user as a file or URL. The User Code Generation is tied to the User.
The 3 new APIs are based on these 3 resources, with each resource having its specific API and each API having many endpoints. These corresponding database models of these resources were also added to the old CodeGen and Transformer APIs as well, to ensure backward compatibility for our public APIs. Increased our score from Level 0 to Level 1. Are we happy with this? Yes; can we go higher? 100%.
HTTP Methods and Status Codes
HTTP has defined a few sets of methods that indicate the type of action to be performed on the resources. The URL is a sentence, where resources are nouns and HTTP methods are verbs. Aspiring to achieve true RESTful-ness for our APIs we used HTTP methods instead of using a single method for all requests, for instance, GET when requesting resources and DELETE when deleting resources, and so on.
// Request:
GET /transformation/1
// Response:
HTTP/1.1 200 OK
{
exportFormat: "APIMATIC"
}Similarly, HTTP has defined a bunch of standardized codes which let the client know the feedback, whether the request failed, passed or the request was wrong. For the sake of correct Developer Experience, our API should always return the right HTTP Status Code. e.g. 200 OK for successful retrieval of resource and 404 Not Found if the requested resource doesn’t exist.
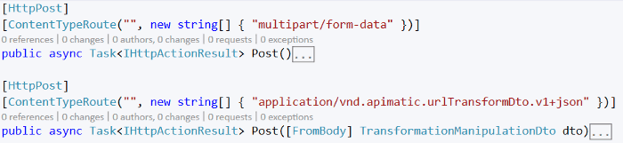
Content-Type based routing
While writing the new APIs we came across a few cases where we needed a different action performed for the same resource and the same HTTP verb e.g. creating (POST) a Transformation with a File and creating (POST) a Transformation with a URL. In such a case where we wanted even finer-grain control over the routing mechanics, we ended up routing them to different actions based on the content-type header. We implemented a custom version of the Route attribute which adds a Content-Type parameter that gets evaluated when a request is being routed. And now we had a single path (e.g. POST: “api/transformations”) that accepts both binary and JSON data and routes them to a different action.
Repository Design Pattern
The new APIs were implemented on the Single Responsibility Rule and the Repository Design Pattern. It leverages a layer that isolates the APIs from the details of the database access code. In large systems such as ours adding this layer helps minimize duplicate query logic. The repository (or as it’s called in our codebase; a manager) acts as an in-memory object collection. Objects are added and removed from the repository and the code encapsulated by the repository carries out the appropriate operations behind the scenes. The API is completely unconcerned about the underlying mechanism of getting the data or even the kind of database being used; it could be a MongoDB or SQL database being accessed inside the repository using whatever ORM or Querying mechanism, the controller would just call the relevant method of the repository to get the data it requires.
Documentation
The new APIs were written to be self-documenting, we tried to make things as self-explanatory as possible. Here’s a work-in-progress version of documentation generated using APIMatic tools: Preview Docs
The taxonomy and naming convention we advised can easily be picked by documentation rendering tools to name our endpoints in a way that even a layman can understand.
Unit Tests
Writing unit tests for code results in fewer bugs in production and fewer bugs in production means more time for making cool new features. It’s usually good practice to have automated unit tests while writing code. Doing so helps find bugs early in the development cycle and saves time in the long run. These tests can be run multiple times to verify the behavior of a particular unit of code for different sets of input.
We used NUnit to write unit tests for the data access layer and plan on expanding test coverage to the rest of the codebase, it’s a good start but we’ve got a long way to go when it comes to automated unit testing.
Hypermedia
Level 3, the highest level, uses HATEOAS to deal with discovering the possibilities of your API for the clients. This is our end goal for the APIs to completely satisfy the REST constraints. We have already started working towards this.
We would soon be launching our new APIs publicly, once they are completely tried and tested. Our product team is working day and night to package them nicely and make them available to our users in a really convenient way. We intend to make all of our services and products super flexible and enable everyone to access and retrieve what they want in form of optimized payloads.
Also a big round of applause for Ammar Naqvi, Software Engineer @ APIMATIC, who played a huge role in reviving our APIs and with whose collaboration this blog was written. Follow him on Twitter @ammarabbasnaqvi.


